Introduction
Back in 2015 I published an article [1] about the QR decomposition of a centrosymmetric real matrix. In 2016 I started thinking about the meaning of this decomposition and centrosymmetric matrices in general. I discovered that centrosymmetric matrices have a natural interpretation as split-complex matrices and even more, that the centrosymmetric QR decomposition of a matrix actually corresponds to a QR decompositon of a split-complex matrix for which the original matrix is it representation. In a certain sense, the centrosymmetric QR decomposition introduced in [1] of a real square matrix of order  is equivalent to a QR decomposition of a corresponding split-complex square matrix of order
is equivalent to a QR decomposition of a corresponding split-complex square matrix of order  . All these notions will be made precise in the following sections. This blog post is based on my own preprint.
. All these notions will be made precise in the following sections. This blog post is based on my own preprint.
Matrix representations
If  is a finite-dimensional vector space then we denote by
is a finite-dimensional vector space then we denote by  the set of all linear transformations
the set of all linear transformations  . Recall that if is an -dimensional vector space and
. Recall that if is an -dimensional vector space and  an ordered basis for , then every linear transformation
an ordered basis for , then every linear transformation  has an
has an  matrix representation with respect to
matrix representation with respect to  denoted
denoted ![[T]_\mathcal{B}](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-9681ac63ba28fe01a34082b913969eed_l3.png "Rendered by QuickLaTeX.com") . Further, for any two linear transformations
. Further, for any two linear transformations  we have
we have ![[S \circ T]_\mathcal{B} = [S]_\mathcal{B} [T]_\mathcal{B}](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-f8a34a6154bbdcbec92f422ac7a4f5bb_l3.png "Rendered by QuickLaTeX.com") . The standard ordered basis for
. The standard ordered basis for  i.e. the basis
i.e. the basis  is defined as
is defined as  if
if  and
and  otherwise.
otherwise.
An algebra  is an ordered pair
is an ordered pair  such that
such that  is a vector space over a field
is a vector space over a field  and
and  is a bilinear mapping called multiplication.
is a bilinear mapping called multiplication.
Let  be an algebra. A representation of over a vector space is a map
be an algebra. A representation of over a vector space is a map  such that
such that
 for all
for all  .
.
Let  denote the set of real matrices. If is an -dimensional vector space and an ordered basis for then every linear transformation
denote the set of real matrices. If is an -dimensional vector space and an ordered basis for then every linear transformation  has a matrix representation
has a matrix representation ![[T]_\mathcal{B} \in M_n(\mathbb{R})](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-5791b83f990fe4853f18a333a6ddcad3_l3.png "Rendered by QuickLaTeX.com") . For each
. For each  we have
we have  . Since is -dimensional, we have and ordered basis and
. Since is -dimensional, we have and ordered basis and ![[\phi(a)]_\mathcal{B} \in M_n(\mathbb{R})](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-cef0b0493a1932fe8a0bc57934c16081_l3.png "Rendered by QuickLaTeX.com") . A matrix representation of with respect to } is a map
. A matrix representation of with respect to } is a map  such that
such that ![\phi_\mathcal{B}(a) = [\phi(a)]_\mathcal{B}](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-0c7f8d77f75011bb6e57fc5e5e1f4d25_l3.png "Rendered by QuickLaTeX.com") for all . Further, we have
for all . Further, we have  for all
for all  . These are all well known notions from representation theory, for further information, one can consult one of the standard textbooks, for example see [3].
. These are all well known notions from representation theory, for further information, one can consult one of the standard textbooks, for example see [3].
Algebra of split-complex numbers
Let  , where
, where  is given by
is given by
(1) 
for all

. It is straightforward to verify that

is
an algebra. This is the well known algebra of
split-complex numbers. The split-complex numbers are also sometimes known as
hyperbolic numbers.
Similarly as for the complex numbers, each real number

can be identified with the pair

.
With this correspondence, the pair

has the property

and

. Due to this property,

is called the
hyperbolic unit.
Since

, in the following we shall denote a pair

simply with

. The
conjugate of

is defined as

.
For a hyperbolic number we define the real part as  and hyperbolic part as
and hyperbolic part as  .
.
For the module we set  and we have
and we have  for all
for all  .
.
For an extensive overview of the theory of hyperbolic numbers as well of their usefulness in Physics one can check the literature, for example [2]. For the rest of this blog post, we shall refer to these numbers as split-complex numbers.
Centrosymmetric representation of split-complex matrices
By  we denote the set of all split-complex matrices i.e. matrices in which entries are split-complex numbers. Note that
we denote the set of all split-complex matrices i.e. matrices in which entries are split-complex numbers. Note that  if and only if there exist real matrices ,
if and only if there exist real matrices ,  such that
such that  . If is a matrix then its transpose is defined as
. If is a matrix then its transpose is defined as  for all
for all  and is denoted with
and is denoted with  . In the following we denote by
. In the following we denote by  the identity matrix and by
the identity matrix and by  the zero matrix. Let
the zero matrix. Let  be defined as
be defined as  for each . Note that
for each . Note that  . A matrix
. A matrix  is upper-triangular if
is upper-triangular if  for all
for all  .
.
A real matrix  is centrosymmetric if
is centrosymmetric if  . An overview of centrosymmetric matrices can be found in [4]. We denote by
. An overview of centrosymmetric matrices can be found in [4]. We denote by  the set of all centrosymmetric real matrices.
the set of all centrosymmetric real matrices.
For the algebra  of split-complex numbers the well-known matrix representation
of split-complex numbers the well-known matrix representation  with respect to
with respect to  is given by
is given by
(2) 
It is straightforward to check that for all
we have

.
Further, on the vector space  there is a natural multiplication operation
there is a natural multiplication operation  given by
given by
(3) 
for all

. It is easy to verify that

is an algebra. In the following we refer to this algebra as the
algebra of split-complex (square) matrices and denote it with

.
Note that in the following whenever we have two matrices  , their product shall explicitly be written with a dot '
, their product shall explicitly be written with a dot ' ', e.g.
', e.g.  to indicate multiplication defined in (3). Otherwise, if
to indicate multiplication defined in (3). Otherwise, if  we simply write
we simply write  .
.
To state and prove our main result, we shall need the following well known characterization of centrosymmetric matrices.
Proposition 1:
Let  . Then
. Then  if and only if there exist
if and only if there exist  such that
such that
(4) 
Proof:
Suppose
![\[A =\begin{bmatrix}X & Y \\W & Z\end{bmatrix}.\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-dfc22a1c4d521ab6264a5e940d168b8b_l3.png "Rendered by QuickLaTeX.com")
Since
is centrosymmetric, we have

, or equivalently, in block-form
*** QuickLaTeX cannot compile formula:
\[\begin{bmatrix}\ & J \\J & \\end{bmatrix}\begin{bmatrix}X & Y \\W & Z\end{bmatrix} =\begin{bmatrix}X & Y \\W & Z\end{bmatrix}\begin{bmatrix}\ & J \\J & \\end{bmatrix}\]
*** Error message:
\begin{bmatrix} on input line 17 ended by \end{equation*}.
leading text: ...begin{bmatrix}\ & J \\J & \\end{bmatrix}\]
Missing $ inserted.
leading text: ...begin{bmatrix}\ & J \\J & \\end{bmatrix}\]
Missing } inserted.
leading text: ...begin{bmatrix}\ & J \\J & \\end{bmatrix}\]
Missing \cr inserted.
leading text: ...begin{bmatrix}\ & J \\J & \\end{bmatrix}\]
Missing $ inserted.
leading text: ...begin{bmatrix}\ & J \\J & \\end{bmatrix}\]
Missing } inserted.
leading text: ...begin{bmatrix}\ & J \\J & \\end{bmatrix}\]
Missing \right. inserted.
leading text: ...begin{bmatrix}\ & J \\J & \\end{bmatrix}\]
Improper \prevdepth.
leading text: \end{document}
Missing $ inserted.
leading text: \end{document}
Missing } inserted.
leading text: \end{document}
This is equivalent to
![\[\begin{bmatrix}JW & JZ \\JX & JY\\end{bmatrix} =\begin{bmatrix}YJ & XJ \\ZJ & WJ\end{bmatrix}\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-dd5627f494d4bca7581085523a98716c_l3.png "Rendered by QuickLaTeX.com")
We now have

and

, so
![\[A = \begin{bmatrix}X & JWJ \\W & JXJ\end{bmatrix}\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-7c3957443d30be0edce1f4d5805ced92_l3.png "Rendered by QuickLaTeX.com")
Now, by choosing

and

and from the fact
it follows that
has the form (4).
Conversely, suppose has the form (4). It can easily be shown by block-matrix multiplication that , hence is centrosymmetric.
QED.
The map  defined as
defined as
(5) 
is a matrix representation of
. We call the representation

the
standard centrosymmetric matrix representation of
.
Proof:
Let  and be such that
and be such that  and
and  .
.
We now have

which proves the claim.
QED.
Proposition.
Let  . Then
. Then  .
.
Proof.
Let  . Then
. Then
![\[{cs}(Q^T) = {cs}(A^T + jB^T) = \begin{bmatrix}A^T & B^T J \\J B^T & J A^T J\end{bmatrix}.\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-50052d6274db4c924f8f8c3e0721d654_l3.png "Rendered by QuickLaTeX.com")
On the other hand, keeping in mind that

we have
![\[{cs}(Q)^T = \begin{bmatrix}A & B J \\J B & JAJ\end{bmatrix}^T =\begin{bmatrix}A^T & (JB)^T \\(BJ)^T & (JAJ)^T\end{bmatrix}= \begin{bmatrix}A^T & B^T J \\J B^T & J A^T J\end{bmatrix}.\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-9714f4b56d03557826eb2b0e6f887b47_l3.png "Rendered by QuickLaTeX.com")
Hence,
.
QED.
Proposition.
The map is a bijection.
Proof.
Injectivity. Let and  and
and  . From this,
. From this,
it follows that  or
or  . Assume that . Then
. Assume that . Then

Since
we have

. Let now
and assume that

. Then from
it follows

. Now multiplying
with

from the left implies

, which is a contradiction.
We conclude that

is injective.
Surjectivity. Let . By proposition 1 we can find matrices and  such that (4) holds. But then
such that (4) holds. But then  and since was arbitrary, we conclude that is surjective.
and since was arbitrary, we conclude that is surjective.
Now, injectivity and surjectivity of imply by definition that is a bijection.
QED.
Correspondence of QR decompositions
Definition:
Let  . A pair
. A pair  with
with  is a QR decomposition of over if the following holds:
is a QR decomposition of over if the following holds:
 is orthogonal, i.e.
is orthogonal, i.e.  ,
,- is upper-triangular,

The notion of a  double-cone matrix was introduced by the author in [1].
double-cone matrix was introduced by the author in [1].
Here we state the definition in block-form for the case of  .
.
Definition:
Let . Then  is a double-cone matrix iff there exist
is a double-cone matrix iff there exist  both upper-triangular such that
both upper-triangular such that
![\[H = \begin{bmatrix}A & BJ \\JB & JAJ\end{bmatrix}.\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-808405c728b3915d63f5080e9576518b_l3.png "Rendered by QuickLaTeX.com")
Definition:
Let  . A pair
. A pair  , with
, with  is a centrosymmetric QR decomposition of
is a centrosymmetric QR decomposition of  if the following holds:
if the following holds:
 is orthogonal matrix,
is orthogonal matrix, is double-cone matrix,
is double-cone matrix,
The algorithm to obtain an approximation of a centrosymmetric QR decomposition of a given centrosymmetric matrix was given in [1].
The following theorem provides one interpretation of the centrosymmetric QR decomposition, in the case of square centrosymmetric matrices of even order by establishing the equivalence of their centrosymmetric QR decomposition with the QR decomposition of the corresponding split-complex matrix.
Theorem 1 (QR decomposition correspondence):
Let  . Then
. Then  is a QR decomposition of if and only if
is a QR decomposition of if and only if
![\[(\CsEmb{Q}, \CsEmb{R}) \in \CsMat{2n} \times \CsMat{2n}\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-e9a458e3f996c705150a04da9762d369_l3.png "Rendered by QuickLaTeX.com")
is a centrosymmetric QR decomposition of

.
Proof.
Let  be a QR decomposition of .
be a QR decomposition of .
Let  and
and  . We have
. We have

Since

it follows that

.
From this we have

i.e.

hence
is orthogonal. Since
is upper-triangular and

, then by definition we have that both

and

are upper-triangular. Further,

is centrosymmetric by definition. From this it follows that
is centrosymmetric double-cone.
Finally, we have

. Hence,

is
a centrosymmetric QR decomposition of

.
Conversely, let  . If is a centrosymmetric QR decomposition of then
. If is a centrosymmetric QR decomposition of then  where is centrosymmetric and orthogonal and is a double-cone matrix.
where is centrosymmetric and orthogonal and is a double-cone matrix.
From the fact that is centrosymmetric we have (by Proposition 1) that
![\[W = \begin{bmatrix}W_1 & W_2 J \\J W_2 & J W_1 J\end{bmatrix}\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-c10ff9bad6cc022b85b4befe7f99a024_l3.png "Rendered by QuickLaTeX.com")
Now the property of
being orthogonal i.e. the condition
implies
(6) 
On the other hand, we have
(7) 
First we prove that
is orthogonal. From (6) we obtain

The matrix
is centrosymmetric and double-cone which implies
![\[Y = \begin{bmatrix}Y_1 & Y_2 J \\J Y_2 & J Y_1 J\end{bmatrix}\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-5788a9be2737c3666186cb5481c37365_l3.png "Rendered by QuickLaTeX.com")
where both

and

are upper-triangular. This now implies that

is upper-triangular.
Finally, let us prove that  . We have
. We have
![\[Q \cdot R = {cs}^{-1} (W) {cs}^{-1} (Y) = {cs}^{-1}(WY) = {cs}^{-1}(\CsEmb{A}) = A.\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-dd022056b2f5c502b64e158d2a87d15e_l3.png "Rendered by QuickLaTeX.com")
We conclude that
is a QR decomposition of
.
QED.
Example:
Let
![\[A = \begin{bmatrix}1 + 2j & 2 + 3j \\3 + 4j & 4 + 5j\end{bmatrix}.\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-db6205a4ba7d1af37703a787ba0df9c9_l3.png "Rendered by QuickLaTeX.com")
Note that

where
(8) 
We have
![\[{cs}(A) = {cs}(W + jZ) = \begin{bmatrix}W & ZJ \\JZ & JWJ\end{bmatrix}= \begin{bmatrix}1 & 2 & 3 & 2 \\3 & 4 & 5 & 4 \\4 & 5 & 4 & 3 \\2 & 3 & 2 & 1\end{bmatrix}\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-1c69ab9d656b5f8fe677e72f6445a893_l3.png "Rendered by QuickLaTeX.com")
By applying the

algorithm from [1] to

we obtain the approximations:

Applying  to and yields:
to and yields:

with

. Now, from Theorem 1 we conclude that

is an approximation of a QR decomposition of
.
Conclusion
We introduced the standard centrosymmetric representation for split-complex matrices. Using this representation we proved that a QR decomposition of a square split-complex matrix can be obtained by calculating the centrosymmetric QR decomposition introduced by the author in [1] of its centrosymmetric matrix representation .
References
- Burnik, Konrad. A structure-preserving QR factorization for centrosymmetric real matrices,
Linear Algebra and its Applications 484(2015) 356 - 378
- Catoni, Francesco and Boccaletti, Dino and Cannata, Roberto and Catoni, Vincenzo and Zampeti, Paolo, Hyperbolic Numbers. Geometry of Minkowski Space-Time Springer Berlin Heidelberg Berlin, Heidelberg, (2011) 3–23 ISBN: 978-3-642-17977-8
- Curtis, Charles W.; Reiner, Irving. Representation Theory of Finite Groups and Associative Algebras, John Wiley & Sons (Reedition2006 by AMS Bookstore), (1962) ISBN 978-0-470-18975
- James R. Weaver. Centrosymmetric (Cross-Symmetric) Matrices,Their Basic Properties, Eigenvalues, and Eigenvectors, The American Mathematical Monthly, Mathematical Association of America, (1985) 10-92, 711–717 ISSN: 00029890, 19300972 doi:10.2307/2323222
QR_decomposition_of_split_complex_matric
Copyright © 2018, Konrad Burnik
 such that it has an infinite metric base
such that it has an infinite metric base  ?"
?" be defined as
be defined as![\[ d((x_1,x_2), (y_1, y_2)) = \max(|x_1 - y_1|, |x_2-y_2|) \]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-b51c1d7bbf1cbf76f190b465b7eaf0da_l3.png "Rendered by QuickLaTeX.com")
 . Then
. Then  is a metric on
is a metric on  , denoted by
, denoted by  and
and  is a metric space.
is a metric space. and the integer lattice
and the integer lattice  as the candidate for such a set. Here I will explain why this set is a good candidate.
as the candidate for such a set. Here I will explain why this set is a good candidate. . Then
. Then  and
and  then
then  . By [1] the space
. By [1] the space ![\{a,b,c\} \in [0,1]\times[0,1]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-f29701da2b3b8cc78270bd0ef03c26f3_l3.png "Rendered by QuickLaTeX.com") such that either
such that either  ,
,  or
or  ,
,  Let
Let  . Then
. Then  is a metric base for
is a metric base for ![([0,1]\times[0,1], d_\infty)](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-df366eed9743baafe1cb4bacf3917b26_l3.png "Rendered by QuickLaTeX.com") .
. and
and  be metric spaces. If
be metric spaces. If  is a metric base for
is a metric base for  and
and  is an onto mapping such that there exists
is an onto mapping such that there exists  with the property
with the property![\[ d_Y(\phi(x), \phi(y)) = \lambda \cdot d_X(x, y), \]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-88a6c4afb0ec03d2578ba66ddf192dcb_l3.png "Rendered by QuickLaTeX.com")
 , then
, then  is a metric base for
is a metric base for  .
.![[\alpha,\beta]\times[\alpha,\beta]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-94194a6281c5a23b4b3d4adc67038e60_l3.png "Rendered by QuickLaTeX.com") where
where  by using the known result of Proposition 1 and finding a suitable map
by using the known result of Proposition 1 and finding a suitable map ![\phi : [0,1]\times[0,1]\rightarrow [\alpha,\beta]\times[\alpha,\beta]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-94b2950adbb51c365f8b1db12ed35614_l3.png "Rendered by QuickLaTeX.com") .
.![\phi :[0,1]\times[0,1] \rightarrow [\alpha,\beta]\times[\alpha,\beta]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-0a61adf22b998c72387930c6a1ff3ed2_l3.png "Rendered by QuickLaTeX.com") where
where  be defined as
be defined as![\[ \phi(x_1,x_2) = ((1-x_1)\alpha + x_1 \beta, (1-x_2)\alpha + x_2 \beta)) \]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-7769aa264aedb618d64b8086e4258360_l3.png "Rendered by QuickLaTeX.com")
![(x_1,x_2) \in [0,1]\times[0,1]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-1766bd7a7cc415827f859497e301cc6e_l3.png "Rendered by QuickLaTeX.com") . Then
. Then  is a metric base for
is a metric base for ![([\alpha,\beta]\times[\alpha,\beta], d_\infty)](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-f5d20340f6c60e497b8221a06aae11a1_l3.png "Rendered by QuickLaTeX.com") .
. it is easy to verify that
it is easy to verify that  defined in Proposition 3 satisfies the property of
defined in Proposition 3 satisfies the property of  . Let
. Let  and assume that
and assume that![\[ d_\infty(x,a) = d_\infty(y,a) \]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-c39ac02d9b45a435cb0fbf92c323a541_l3.png "Rendered by QuickLaTeX.com")
 such that
such that  and
and ![x, y \in [\alpha,\beta]\times[\alpha,\beta]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-635172485a28553eb27b43b2ea04e795_l3.png "Rendered by QuickLaTeX.com") . Namely, we can take for example
. Namely, we can take for example  such that
such that  and set
and set  . Now set
. Now set  and
and  .
.![[0,1]\times[0,1]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-5602637ae1d1e47246cfd71d1fe97e73_l3.png "Rendered by QuickLaTeX.com") are a metric base for
are a metric base for  , then
, then  for all
for all  implies
implies  .
. be such that for all
be such that for all  the following implication holds:
the following implication holds: ![\[\left(\forall a \in A \ d(x,a) = d(a,y) \right) \implies x=y\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-c01edba452e7bdeb202b01cb39c6b70f_l3.png "Rendered by QuickLaTeX.com")
 in
in  is called a dense sequence iff
is called a dense sequence iff  is a
is a  . Let
. Let  . Suppose
. Suppose  for all
for all  in
in  . This is equivalent to
. This is equivalent to  . Since
. Since  .
. ,
,  and
and  for all
for all  . From the triangle inequality and non-negativity of the metric we now have
. From the triangle inequality and non-negativity of the metric we now have  for all
for all  and
and  , we have by the
, we have by the  , therefore
, therefore  which implies
which implies  . We conclude that
. We conclude that  that contains a metric base is a metric base. What about metric bases which are not dense in
that contains a metric base is a metric base. What about metric bases which are not dense in ![I = [0,1]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-310ce3e3cca609d492097b10357d9a58_l3.png "Rendered by QuickLaTeX.com") . We define the metric
. We define the metric ![\[ d_\infty((x_1,x_2), (y_1,y_2)) = \max (|x_1 - y_1|, |x_2 - y_2|).\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-687fa8154c57471a841f00e8f46f4d09_l3.png "Rendered by QuickLaTeX.com")
 . Let
. Let  .
. and
and  . Suppose
. Suppose  is a sequence in
is a sequence in  such that the sequences
such that the sequences  and
and  are computable sequences
are computable sequences  ? Does the sequence
? Does the sequence 
 where
where  is an incomputable real. Then
is an incomputable real. Then  however,
however,  and
and  . Let
. Let  ,
,  and
and  are computable sequences
are computable sequences  be a computable sequence in
be a computable sequence in  . Let
. Let  be a computability structure induced by
be a computability structure induced by  . Since
. Since  where
where  is an incomputable real. Then the finite sequence
is an incomputable real. Then the finite sequence  has the property
has the property  hence by definition
hence by definition ![\[T = \{(a,a,a,\dots), (b,b,b,\dots), (c,c,c,\dots)\}\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-ab6375a824214c244c5f81db158c6e63_l3.png "Rendered by QuickLaTeX.com")
 such that
such that  and
and  are computable points in
are computable points in  is not computable in
is not computable in  is a non-computable real. This is equivalent to the fact that
is a non-computable real. This is equivalent to the fact that  . Therefore,
. Therefore,  . From this we conclude that
. From this we conclude that  and
and  are computable.
are computable.
![\[ (i,j) \mapsto d(x_i, x_j) \]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-91f234d45af03859f15a89db670aa197_l3.png "Rendered by QuickLaTeX.com")
 is an effective finite sequence if
is an effective finite sequence if  is a recursive real number for each
is a recursive real number for each  .
. are sequences in
are sequences in  is an effective pair in
is an effective pair in  if the function
if the function ![\[ (i,j) \mapsto d(x_i, y_j) \]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-ec79f8392d67775363f0fc6dbfddaf40_l3.png "Rendered by QuickLaTeX.com")
 is computable w.r.t
is computable w.r.t  such that
such that![\[ d(y_i, x_{F(i, k)}) < 2^{-k} \]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-76c2a60cd814845e0693dd4186a16b91_l3.png "Rendered by QuickLaTeX.com")
 . We write
. We write  .
. is a computability structure on
is a computability structure on  , then
, then  and
and  , then
, then 
 is a computable point in
is a computable point in  iff
iff  .
. is called separable.
is called separable. such that
such that  and
and  .
. . Let
. Let  are computable. Under which conditions is such
are computable. Under which conditions is such  are geometrically independent points if
are geometrically independent points if  are linearly independent vectors.
are linearly independent vectors. . The largest
. The largest  such that that there exist geometrically independent points
such that that there exist geometrically independent points  we call the affine dimension of
we call the affine dimension of  .
. ,
,  and
and  . If
. If  is a geometrically independent effective finite sequence on
is a geometrically independent effective finite sequence on  is called a metric base for
is called a metric base for  for all
for all  implies
implies  such that
such that![\[X=B(\alpha _{0} ,2^{-k})\cup \dots \cup B(\alpha _{f(k)},2^{-k})\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-5e70f2dc5b8fe0f958c67919c9d02c9a_l3.png "Rendered by QuickLaTeX.com")
 . It is known that if
. It is known that if  .
. is a metric base in
is a metric base in  has the effective covering property.
has the effective covering property. to
to  and enforcing i different from 1? We get the somewhat less known numbers called
and enforcing i different from 1? We get the somewhat less known numbers called 

 is computable. For example, a definition of computable point is a generalization of the computable real: A point
is computable. For example, a definition of computable point is a generalization of the computable real: A point  is computable in
is computable in  such that
such that  for every
for every  be a fixed such enumeration. Then for a set
be a fixed such enumeration. Then for a set  is recursively enumerable
is recursively enumerable  is recursively enumerable i.e. there exists a computable function
is recursively enumerable i.e. there exists a computable function  . A subset
. A subset  such that
such that  . A subset
. A subset 
 are computable.
are computable.  are computable? (note the domain and codomain are now the reals).
are computable? (note the domain and codomain are now the reals).

 of
of  "converges fast" to
"converges fast" to  is computable iff there exists a computable function
is computable iff there exists a computable function  such that
such that  for each
for each  is computable, and in our previous post we
is computable, and in our previous post we  is computable. It turns out that the set of computable reals, denoted by
is computable. It turns out that the set of computable reals, denoted by  is a field with respect to addition and multiplication. But there exist real numbers which are not computable. This is easy to see as there is only a countable number of computable functions
is a field with respect to addition and multiplication. But there exist real numbers which are not computable. This is easy to see as there is only a countable number of computable functions  , and since we know that
, and since we know that  is uncountable, so we have more real numbers than we have possible algorithms, we conclude that there must be a real number that is not computable. One example of an uncomputable real is the limit of a
is uncountable, so we have more real numbers than we have possible algorithms, we conclude that there must be a real number that is not computable. One example of an uncomputable real is the limit of a  , then the number
, then the number  is an example of a real number which is not computable.
is an example of a real number which is not computable. (and hence a sequence of algorithms) we may ask if this sequence is computable i.e. is there a single algorithm that describes the whole sequence? If there exists a computable function
(and hence a sequence of algorithms) we may ask if this sequence is computable i.e. is there a single algorithm that describes the whole sequence? If there exists a computable function  such that
such that ![\[ |f(n,k) - x_n| < 2^{-k}\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-c978eb2ae7c2e28068828507f9e9a4f8_l3.png "Rendered by QuickLaTeX.com")
 then we say that
then we say that  be a one-to-one recursive function which enumerates
be a one-to-one recursive function which enumerates  be given by
be given by![\[ f(n) = 2^{-m}, \mbox{ if } m = a(n) \mbox{ for some } m \\, 0 \mbox{ otherwise. } \]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-cef76b066ae9a8ee4c4d18a8237d3519_l3.png "Rendered by QuickLaTeX.com")
 is computable iff
is computable iff  is computable for every computable sequence
is computable for every computable sequence 
![\[\chi_S(x) =\begin{cases} 1, & x \in S \\ 0, & x \not \in S \end{cases}\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-064bd0cca97592aa71745aad2444c6ab_l3.png "Rendered by QuickLaTeX.com")
 or
or  . A subset
. A subset  defined as
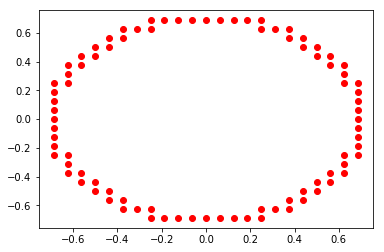
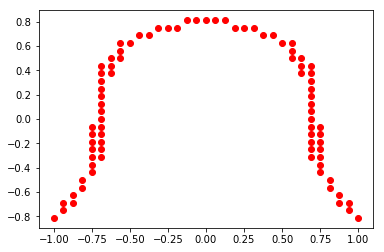
defined as  is a computable function. For example, take the unit circle in
is a computable function. For example, take the unit circle in ![\[\mathbb{S}^1 = \{(x,y): x^2 + y^2 =1\}\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-d080c9c7c0df9960c0870bc49a444e40_l3.png "Rendered by QuickLaTeX.com")
![\[d((x,y), \mathbb{S}^1) = |x^2 + y^2 - 1|, \forall x,y \in \mathbb{R}^2.\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-5700fe7f0ac21cebea58fa05eb6e6a04_l3.png "Rendered by QuickLaTeX.com")
 for
for  , The question I was interested was "What is the least number of segments of length
, The question I was interested was "What is the least number of segments of length ![\[2, 3, 6, 12, 23, 46, 91, 182, 363, 725,\dots.\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-e0fc94c01da00342e00775693d25f446_l3.png "Rendered by QuickLaTeX.com")
 (within k-bits of precision), but is this sequence computable? In what follows I assume that the reader is familiar with the basic definitions of
(within k-bits of precision), but is this sequence computable? In what follows I assume that the reader is familiar with the basic definitions of 
![\[f(k) = \mu.n [n^2 > 2^{(2k+1)}]\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-aefe2e6f0a40eb584c47d92fcddf26cf_l3.png "Rendered by QuickLaTeX.com")
 .
. it outputs the number of
it outputs the number of  is the smallest integer such that
is the smallest integer such that  we have
we have![\[(f(k) - 1)/2^k < \sqrt{2} < f(k)/2^k\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-34065433a7eb98a9168ffef91a90547b_l3.png "Rendered by QuickLaTeX.com")
 .
. .
. but what we want is to avoid division. We want to calculate only with natural numbers!
but what we want is to avoid division. We want to calculate only with natural numbers! is about twice as large as
is about twice as large as ![\[k > \lceil n log_2 10 \rceil.\]](https://konrad.burnik.org/wordpress/wp-content/ql-cache/quicklatex.com-d9d8f6fc43e39e59ba3a1628d09fbade_l3.png "Rendered by QuickLaTeX.com")
 to get a natural number with all of it's digits being an approximation of
to get a natural number with all of it's digits being an approximation of